Mysql建表
use demo;
create table if not exists module
(
id bigint unsigned auto_increment not null comment 'id',
code varchar(200) default '100' not null comment 'code',
deleted tinyint default 0 not null comment '是否删除;1是 0否',
create_user_id varchar(100) not null comment '创建者id',
update_user_id varchar(100) not null comment '修改者id',
create_time timestamp default CURRENT_TIMESTAMP not null comment '创建时间',
update_time timestamp default CURRENT_TIMESTAMP not null on update CURRENT_TIMESTAMP comment '修改时间',
primary key (id), # 设置主键(联合主键:primary key (id, code))
[unique|fulltext|spatial] index unq_code (code) # 设置索引示例(多种)
) engine = innodb # 存储引擎
# auto_increment = 6 id自增起点为7
default charset = utf8 # 数据库字符集
collate = utf8_general_ci # 数据库校对规则
comment = '模块资源表';Mysql字段类型
常用的字段类型大致可以分为数值类型、字符串类型、日期时间类型三大类,下面我们按照分类依次来介绍下。
1.数值类型
数值类型大类又可以分为整型、浮点型、定点型三小类。
整型主要用于存储整数值,主要有以下几个字段类型:
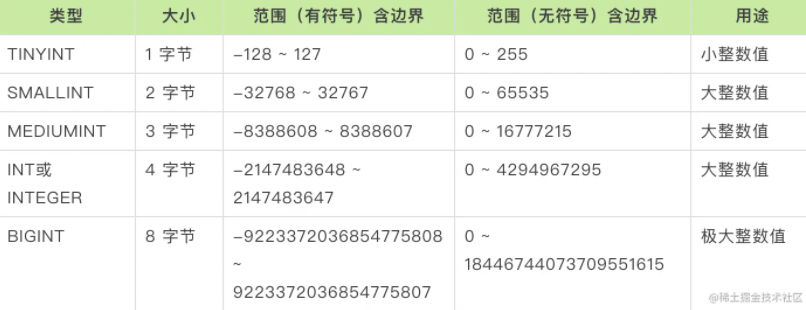
整型经常被用到,比如 tinyint、int、bigint 。默认是有符号的,若只需存储无符号值,可增加 unsigned 属性。
int(M)中的 M 代表最大显示宽度,并不是说 int(1) 就不能存储数值10了,不管设定了显示宽度是多少个字符,int 都是占用4个字节,即int(5)和int(10)可存储的范围一样。
存储字节越小,占用空间越小。所以本着最小化存储的原则,我们要尽量选择合适的整型,例如:存储一些状态值或人的年龄可以用 tinyint ;主键列,无负数,建议使用 int unsigned 或者 bigint unsigned,预估字段数字取值会超过 42 亿,使用 bigint 类型。
浮点型主要有 float,double 两个,浮点型在数据库中存放的是近似值,例如float(6,3),如果插入一个数123.45678,实际数据库里存的是123.457,但总个数还以实际为准,即6位,整数部分最大是3位。 float 和 double 平时用的不太多。

定点型字段类型有 DECIMAL 一个,主要用于存储有精度要求的小数。

DECIMAL 从 MySQL 5.1 引入,列的声明语法是 DECIMAL(M,D) 。 NUMERIC 与 DECIMAL 同义,如果字段类型定义为 NUMERIC ,则将自动转成 DECIMAL 。
对于声明语法 DECIMAL(M,D) ,自变量的值范围如下:
- M是最大位数(精度),范围是1到65。可不指定,默认值是10。
- D是小数点右边的位数(小数位)。范围是0到30,并且不能大于M,可不指定,默认值是0。
例如字段 salary DECIMAL(5,2),能够存储具有五位数字和两位小数的任何值,因此可以存储在salary列中的值的范围是从-999.99到999.99。
2.字符串类型
字符串类型也经常用到,常用的几个类型如下表:
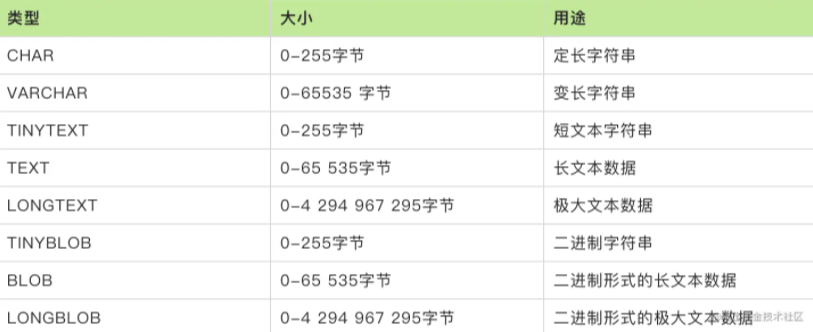
其中 char 和 varchar 是最常用到的。char 类型是定长的,MySQL 总是根据定义的字符串长度分配足够的空间。当保存 char 值时,在它们的右边填充空格以达到指定的长度,当检索到 char 值时,尾部的空格被删除掉。varchar 类型用于存储可变长字符串,存储时,如果字符没有达到定义的位数,也不会在后面补空格。
char(M) 与 varchar(M) 中的的 M 表示保存的最大字符数,单个字母、数字、中文等都是占用一个字符。char 适合存储很短的字符串,或者所有值都接近同一个长度。例如,char 非常适合存储密码的 MD5 值,因为这是一个定长的值。对于字符串很长或者所要存储的字符串长短不一的情况,varchar 更加合适。
我们在定义字段最大长度时应该按需分配,提前做好预估,能使用 varchar 类型就尽量不使用 text 类型。除非有存储长文本数据需求时,再考虑使用 text 类型。
BLOB 类型主要用于存储二进制大对象,例如可以存储图片,音视频等文件。日常很少用到,有存储二进制字符串时可以考虑使用。
3.日期时间类型
MySQL支持的日期和时间类型有 YEAR 、TIME 、DATE 、DATETIME 、TIMESTAMP,几种类型比较如下:

涉及到日期和时间字段类型选择时,根据存储需求选择合适的类型即可。
关于 DATETIME 与 TIMESTAMP 两种类型如何选用,可以按照存储需求来,比如要求存储范围更广,则推荐使用 DATETIME ,如果只是存储当前时间戳,则可以使用 TIMESTAMP 类型。不过值得注意的是,TIMESTAMP 字段数据会随着系统时区而改变但 DATETIME 字段数据不会。总体来说 DATETIME 使用范围更广。
总结:
Mysql中数据类型括号中的数字代表的含义
字符和字节的概念。
字节(Byte)是一种计量单位,表示数据量多少,它是计算机信息技术用于计量存储容量的一种计量单位。
字符是指计算机中使用的文字和符号,比如1、2、3、A、B、C、~!·#¥%……—*()——+、,中,国等等。
字符和字节不存在绝对的关系,只是在不同的编码格式里,对应的比值不一样。比如:
1.UTF-8编码中,一个英文字符等于一个字节,一个中文(含繁体)字符等于三个字节。
2.Unicode编码中,一个英文等于两个字节,一个中文(含繁体)字符等于两个字节。
符号:英文标点占一个字节,中文标点占两个字节。举例:英文句号“.”占1个字节的大小,中文句号“。”占2个字节的大小。
3.UTF-16编码中,一个英文字母字符或一个汉字字符存储都需要2个字节(Unicode扩展区的一些汉字存储需要4个字节)。
4.UTF-32编码中,世界上任何字符的存储都需要4个字节。
char和varchar括号中的数字含义。
char的列长度是固定的,char的长度可选范围在0-255字符之间。也就是char最大能存储255个字符.
varchar的列长度是可变的,在mysql5.0.3之前varchar的长度范围为0-255字符,mysql5.0.3之后varchar的长度范围为0-65535个字节.
CHAR(M)定义的列的长度为固定的,M取值可以为0-255之间,当保存CHAR值时,在它们的右边填充空格以达到指定的长度。当检索到CHAR值时,尾部的空格被删除掉。在存储或检索过程中不进行大小写转换。CHAR存储定长数据很方便,CHAR字段上的索引效率级高,比如定义char(10),那么不论你存储的数据是否达到了10个字符,都要占去10个字符的空间,不足的自动用空格填充。
VARCHAR(M)定义的列的长度为可变长字符串,VARCHAR的最大有效长度由最大行大小和使用的字符集确定。整体最大长度是65,532字节。VARCHAR值保存时不进行填充。当值保存和检索时尾部的空格仍保留,符合标准SQL。varchar存储变长数据,但存储效率没有CHAR高。如果一个字段可能的值是不固定长度的,我们只知道它不可能超过10个字符,把它定义为 VARCHAR(10)是最合算的。VARCHAR类型的实际长度是它的值的实际长度+1。为什么”+1″呢?这一个字节用于保存实际使用了多大的长度。从空间上考虑,用varchar合适;从效率上考虑,用char合适,关键是根据实际情况找到权衡点。
简单来说:varchar(m)里面表示的是长度,例如:varchar(5)表示最大可存储5个中文或5个英文字母。
int smallint等数据类型括号中的数字含义。
| 类型 | 大小 | 范围(有符号) | 范围(无符号) | 用途 |
| TINYINT | 1字节 | (-128,127) | (0,255) | 小整数值 |
| SMALLINT | 2字节 | (-32 768,32 767) | (0,65535) | 大整数值 |
| MEDIUMINT | 3字节 | (-8 388 608,8 388 607) | (0,16 777 215) | 大整数值 |
| INT | 4字节 | (-2 147 483 648,2 147 483 647) (0,4 294 967 295) | (0,4 294 967 295) | 大整数值 |
| BIGINT | 8字节 | (-9 233 372 036 854 775 808,9 223 372 036 854 775 807) | (0,18 446 744 073 709 551 615) | 极大整数值 |
这些类型,是定长的,其容量是不会随着后面的数字而变化的,比如int(11)和int(8),都是一样的占4字节。tinyint(1)和tinyint(10)也都占用一个字节。
那么后面的11和8,有啥用呢。
数据类型(m)中的m不是表示的数据长度,而是表示数据在显示时显示的最小长度。tinyint(1) 这里的1表示的是 最短显示一个字符。tinyint(2) 这里的2表示的是 最短显示两个字符。
当字符长度(m)超过对应数据类型的最大表示范围时,相当于啥都没发生;
当字符长度(m)小于对应数据类型的表示范围时,就需要指定拿某个字符来填充,比如zerofill(表示用0填充),
设置tinyint(2) zerofill 你插入1时他会显示01;设置tinyint(4) zerofill 你插入1时他会显示0001。
即使你建表时,不指定括号数字,mysql会自动分配长度:int(11)、tinyint(4)、smallint(6)、mediumint(9)、bigint(20)。
Mysql索引
创建索引
# 创建索引
# 1.create index
# 1.1 格式
# create [unique|fulltext|spatial] index index_name
# [using index_type]
# on table_name (index_colname...)
# 1.2 参数说明
# [unique|fulltext|spatial]:代表唯一、全文、空间索引,默认为普通类型
# index_name :索引名称 自定义
# [using index_type]:索引的具体实现方式
# Mysql有两种,BTREE索引和HASH索引
# 存储引擎为MyISAM和InnoDB的表中只能使用BTREE,其默认值就是BTREE;
# 在存储引擎为MEMORY或者HEAP的表中可以使用HASH和BTREE两种类型的索引,其默认值为HASH。
# table_name :表名
# index_colname:需要创建所以索引的字段名
# 多字段符合索引用逗号隔开
# 对于char和varchar可以使用字段内容前几个字符创建索引
# 1.3 实例:
create index cust_name_index on customers (cust_name(2));
# 2.alter table 修改表结构
# 2.1 格式
# alter table table_name add [unique|fulltext|spatial] index index_name
# (index_colname...) [using index_type]
# 2.2 实例
alter table customers add index cust_name_index (cust_name(2));删除索引
# 删除索引
# 1.drop index
# 1.1 格式
# drop index index_name on table_name;
drop index cust_name_index on customers;
# 2.alter table
# 2.1 格式
# alter table table_name drop index index_name;
alter table customers drop index cust_name_index;修改索引
修改索引:先删除后再重新创建同名的索引
查看索引
# 查看索引
# 格式
# show index from table_name from db_name;
show index from customers from customers;Mysql explain 各字段解释
下面我们以一个查询语句展示

- id: 行标识,如果没有子查询或者联合查询,这个值是1。
- select_type: 标识查询是简单查询还是复杂查询.(SIMPLE(简单查询),UNION(union语句的查询),SUBQUERY(子查询),DERIVED等(派生表的select))
- table: 显示查询哪个表
- partitions: 显示分区表命中的分区情况
- type: 访问类型,决定如何查询表中的数据(ALL, index, range, ref, eq_ref, const, system, NULL 性能由低到高)
- possible_keys: 查询涉及到的字段上若存在索引,但不一定被查询使用
- key: 显示MySQL实际决定使用的键(索引)
- key_len: 索引中使用的字节数,可通过该列计算查询中使用的索引的长度
- ref: 查询关联, 显示表在key 列记录的索引中查找值所用的列或者常量
- rows:根据表统计信息及索引选用情况,估算找到所需的记录需取的行数
- filtered:估算符合条件的行数除以rows的百分比
- extra: 额外信息
以上这些最重要的是type, possible_keys, key, rows, extra 我们再一次详细介绍这几个字段。
type
- All: 全表扫描
- index: 按索引次序全表扫描
- range: 索引范围扫描
- ref: 索引等值查询(树查找)
- eq_ref: 唯一索引上等值查询
- const: 主键上等值查询
- system: 表只有一条记录
- null: 在优化器阶段分解语句,可能不需要查表就能得到结果,例如查索引字段的最小值

possible_keys
优化器可选择的索引,会将全部索引列出来,我们知道mysql由于性能原因没有实时得到所有索引的全部数据进行比较择优,优化器进行索引选择时是根据选取部分数据页估算出索引的区分度和选择性,估算出一个最优索引,所以有些sql在某种情况下mysql会选错索引(使用其他索引效率会更高),这时我们可以使用force index()强制指定某个索引或者使用其他优化手段,来优化sql
key
优化器最终选择的索引,可以凭自己对表数据的了解,知道是否使用错索引
rows
根据表统计信息及索引选用情况,估算找到所需的记录需要取的行数
extra
一些额外的补充信息,包括但不限一下几种
- using index: 表示使用索引覆盖。
- Using temporary:表示MySQL需要使用临时表来存储结果集,常见于排序和分组查询
- Using filesort:MySQL会对结果使用一个外部索引排序。而不是按索引次序从表里读取。
- Using join buffer:改值强调了在获取连接条件时没有使用索引,并且需要连接缓冲区来存储中间结果。如果出现了这个值,那应该注意,根据查询的具体情况可能需要添加索引来改进。
Click here to view the copyright notice of this site(点击此处查看本站版权声明)
必须 注册 为本站用户, 登录 后才可以发表评论!